How Plan Caching Reduces LLM Agent Costs
Plan caching reuses planning templates across similar agent tasks, cutting cost and latency without throwing away accuracy.
Every time your agent tackles a new task, it plans from scratch. Even when it has solved the same kind of problem a hundred times before.
When an agent receives a task, it has to first figure out how to solve it: what steps to take, what tools to call, what to do with the results. This “figuring out” is the planning stage, during which the model generates a reasoning or thinking chain. Sometimes this chain can be hundreds of tokens long before any single tool is called.
A fascinating insight is that different tasks can share the same plan structure.
For example, “what is the working capital ratio for Costco in FY2019” and “what is the working capital ratio for Best Buy in FY2021” are different tasks. They have different companies, years, and even different numbers, but the plan is identical: you retrieve the current assets, retrieve current liabilities, and then divide.
It turns out plans are reusable artefacts in agentic systems, but we just never thought to cache them.
Some researchers at Stanford thought about this, and they called it Agentic Plan Caching.

Figure from Zhang et al. (2025), Cost-Efficient Serving of LLM Agents via Test-Time Plan Caching.
The idea is simple. You extract plan templates from completed agent executions and then reuse them across similar tasks. In their first version, they use exact keyword matching.
In their experiments, this caching reduced costs by about 50% while maintaining 96% of accuracy.
People working on LLM cost optimisation tend to think about two layers: the KV cache and semantic caching, but plan caching is a third layer and it is arguably the most overlooked.
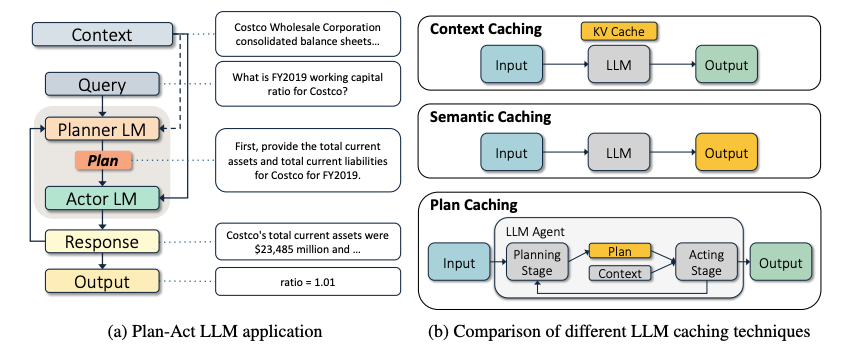
Figure from Zhang et al. (2025), Cost-Efficient Serving of LLM Agents via Test-Time Plan Caching.
I find this idea very fascinating and I’m planning a future post to go into the implementation deeply.
One open question I have, though, is how do you know when a cached plan is close enough to reuse safely? If you get it wrong, you’re applying the wrong method to a task that actually needs fresh thinking.
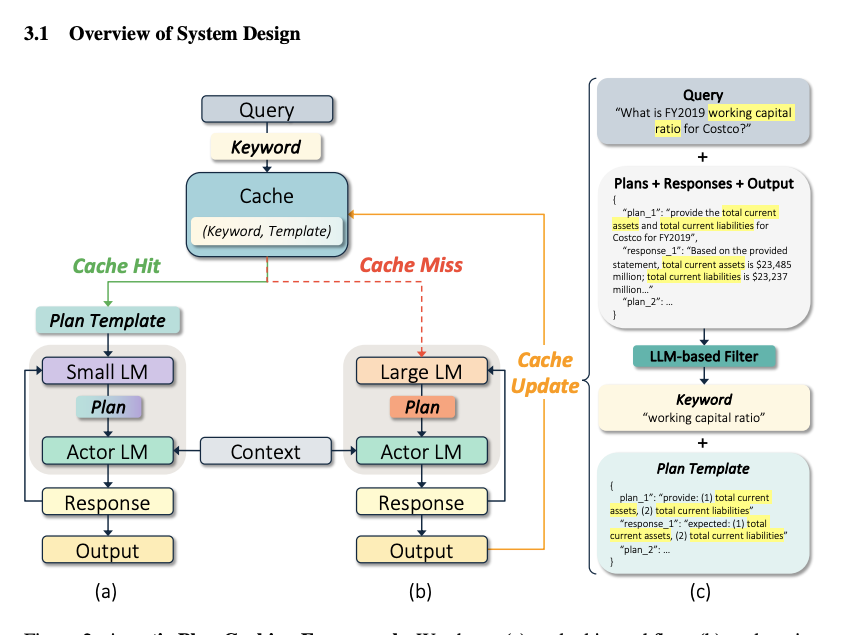
Figure from Zhang et al. (2025), Cost-Efficient Serving of LLM Agents via Test-Time Plan Caching.
Would love to hear your thoughts!
Paper source: Zhang et al. (2025), Cost-Efficient Serving of LLM Agents via Test-Time Plan Caching