A beginner-friendly guide to the GGUF model format
GGUF made local LLM inference feel practical by packaging model weights, vocabulary, hyperparameters, and architecture metadata into one runnable format.
Just a few years ago, running a large language model on your laptop sounded impossible. These models lived in datacenters, behind APIs, and were surrounded by crazy expensive hardware. Today, you can download an LLM through Ollama or LMStudio and start interacting with it in minutes. The model file you interact with on these platforms usually has the extension .gguf.
But what is GGUF, and why does it matter? Well, this article is about how this file format came to be, and it is also my public attempt to study this topic, so let’s dive in.
First, let’s understand how models were saved and transferred in the past.
A few years ago, model files were tightly coupled to the framework that produced them. I remember training neural networks with PyTorch in 2018 and serialising the model with pickle (Python’s general-purpose object serializer). On my machine, this stored both the model weights and the instructions (op-codes) needed to reconstruct them as Python objects.
Now, this approach worked, but it had two problems. First, those op-codes were executable code, which meant that downloading a model from an untrusted source could run arbitrary, potentially unsafe code on your machine. Second, the file was tied to PyTorch, so other frameworks, like TensorFlow, couldn’t read it. These frameworks had their own formats and expectations of model weights.
To address the safety problem, Hugging Face created Safetensors in 2022. The format had a declarative approach: the model file describes what’s in it but doesn’t contain any executable instructions to run on load. The file consisted of a JSON header describing each tensor’s name, type, shape, and location, followed by the raw tensor bytes themselves. To load the file, a reader parsed the header and then read the bytes it pointed to. Further, Safetensors had loaders for various libraries like PyTorch, NumPy, and TensorFlow, so the same file could be read across frameworks. Note that to actually run a model, though, you still needed the architecture code - the part which says “use these weights and arrange them into a transformer of this shape”. That code lived outside your Safetensors file.
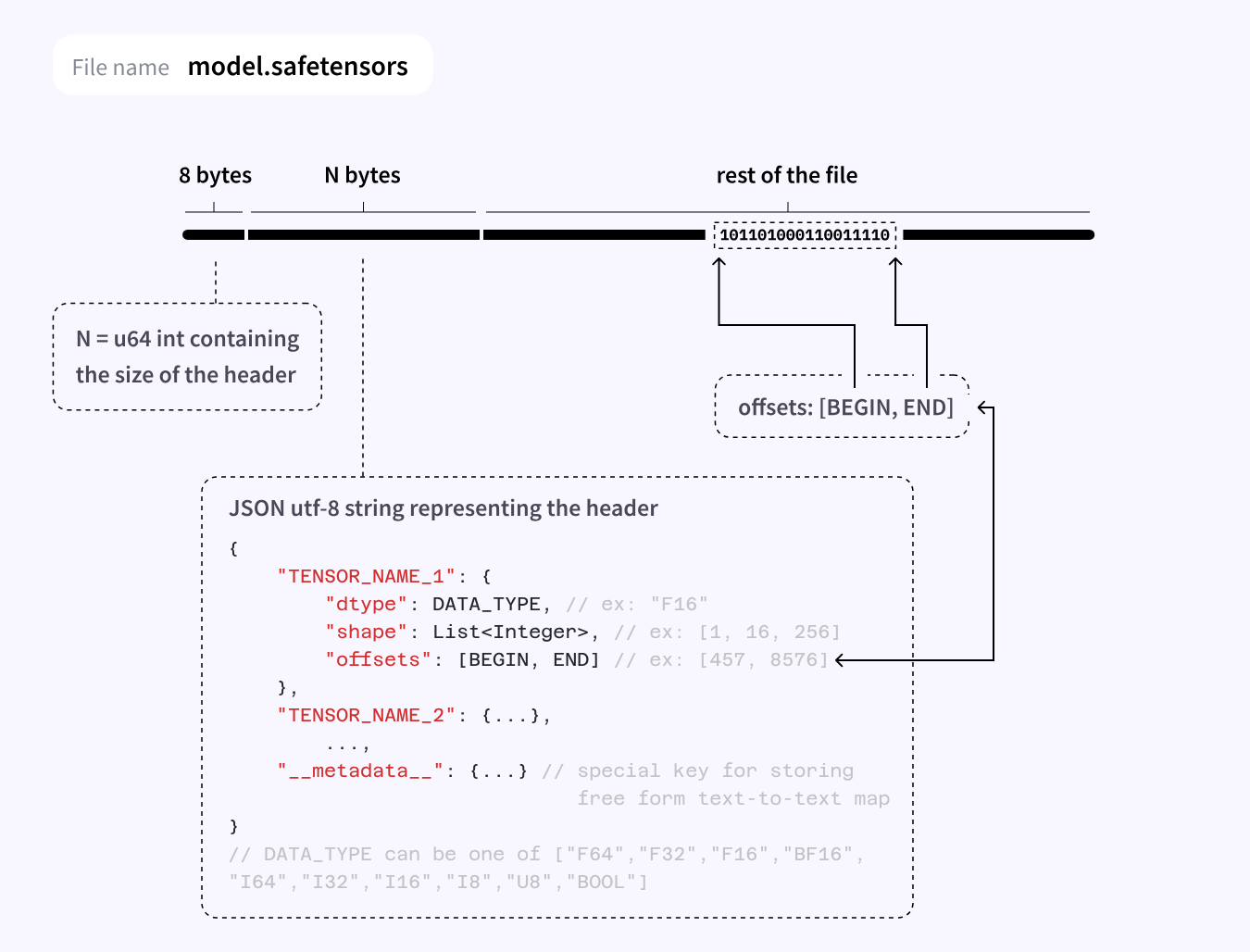
Source: Hugging Face Safetensors documentation.
Safetensors, in other words, solved the safe-loading problem but didn’t solve the harder problem: a file full of weights still isn’t a runnable model on its own.
Meanwhile, a software engineer named Georgi Gerganov was working on a different question: how could we run transformer models on standard hardware? In September 2022, he created the GGML (often read as Georgi Gerganov Machine Learning) library. This was a general tensor library, in the same broad category as PyTorch or TensorFlow but more minimalist and low-level, with a focus on running transformer models. He used it first to build whisper.cpp, an implementation of OpenAI’s Whisper speech-to-text model. When Meta released LLaMA in March 2023, he applied the same approach to language models, building llama.cpp - an LLM inference engine - on top of the same library.
Remember that previously, you needed large, expensive GPUs to run models. Georgi wanted to change this.
To do this, llama.cpp needed a way to store and load model weights, so a new format emerged and, guess what, it was named GGML as well. This format crucially supported quantisation, compressing model weights from 16-bit floats down to 4 or 5 bits each. And this was what actually made local inference possible: a large language model in full precision is too big to fit on a consumer machine but, quantised down to 4 bits, it fits in a high-end laptop’s RAM. Models in the GGML format could be loaded by the GGML library and the executors built on it, like llama.cpp. For the first time, the answer to “can I run this on my machine?” was yes.
For a quick recap, both GGML and Safetensors were declarative and self-describing. They included no instructions to run, but they had different interpreters and philosophies. Safetensors files could be read by loaders from various libraries like PyTorch and NumPy, and the model could then run inside any of those. GGML files needed a GGML-compatible executor like llama.cpp. Also, Safetensors focused on general-purpose model sharing while GGML was specifically built for running transformer models on local machines.
Over time, as newer model architectures were converted to GGML, the format had to be modified over and over to accommodate them. Sometimes, these modifications broke backwards compatibility with models it had supported before. GGML, over different versions, started playing catch-up.
To understand why the GGML format broke backwards compatibility, let’s understand the format.
GGML files were laid out as a flat sequence of fields in a fixed order: a magic number, then a list of hyperparameters, like number of vocab tokens, embedding dimension, layer count, and so on, then the embedded vocabulary, then the tensors themselves. Each field’s meaning was determined by its position. Adding a new hyperparameter meant changing that fixed structure, which broke older readers. At one point, the project resorted to encoding the quantisation version into the lower digits of an existing integer field - the quantisation version became ftype / 1000 because there was nowhere clean to put it.
There was a deeper problem, too: there was no information in the model file at all about what kind of model it was. A LLaMA file and a Falcon file could look structurally the same - same format, just different numbers and names inside. The reader had to know in advance what architecture it was dealing with.
To solve both problems, GGUF was created in August 2023.
Instead of a fixed list of hyperparameters in a specific order, GGUF used a key-value dictionary. Now new keys, or hyperparameters, could be added without breaking older readers, who would simply ignore anything they didn’t recognise. The format also required a general .architecture field so a file finally shared what kind of model it was. Everything needed to load a model now lived in a single file.
The GGUF format, in addition to the GGML library and the executors built on it like llama.cpp, reshaped what is possible with running transformer models on standard hardware. Libraries like Ollama and LMStudio are built on top of this stack.

Credit: diagram by Mishig.
To wrap up, here are some implications.
- You can develop your transformer models using PyTorch, TensorFlow, or other supported tensor libraries, then convert them to GGUF using converter scripts. Anyone with llama.cpp or another GGML-based executor can run inference on those models locally.
- As of February 2026, the GGML team is now part of Hugging Face, which means that the major hub for model distribution and the largest run-transformer-models-on-your-computer ecosystem work hand in hand. New models reach the GGUF ecosystem faster than before.
Now GGUF is not a silver bullet, though. There are things it was not designed for, and there are some real limitations.
- GGUF is designed for inference - for loading models to run, not for checkpointing models. There’s no native support for things like storing optimiser state or learning rate, for instance.
- The architecture list is finite and curated. Currently, it includes support for llama, falcon, mamba, and others, but adding a new architecture means adding it to the spec, defining its required keys, and writing the C++ code in llama.cpp.
Looking back at this lineage, the temptation is to read it as a single race that GGUF eventually won. I don’t think that’s correct. The formats answer different questions.
Pickle is Python’s general-purpose object serializer. Models ended up in pickle files because models were Python objects, not because anyone designed pickle for them. Safetensors is a safe container for tensors - any tensors, from any framework - and it deliberately stops there. The architecture code lives elsewhere. GGUF is the packaging format for a specific runtime: it bundles weights, vocabulary, hyperparameters, and architecture identifier into one file that GGML-based executors know how to run.
So the lineage isn’t really a sequence of attempts at the same goal.
When I started writing this, I wanted to know how the .gguf extension came to be. My study showed that it came about by asking a narrower question than pickle or Safetensors were asking: not “how do we serialize this thing” or “how do we store tensors safely”, but “how do we ship a runnable transformer to a consumer machine?” Narrower questions get sharper answers. GGUF is a sharp answer - for now.
One thing this article didn’t really get into deliberately is quantisation - one of the components which makes it possible to fit large models on consumer hardware in the first place. I want to understand it properly, but that’s for another learning-in-public article.
Massive thanks to Georgi and team for working on this.