Why reranking matters with cross-encoders
Bi-encoders make retrieval fast, but cross-encoders expose why reranking matters when meaning depends on the query.
I was reading about vector retrieval the other week and came across cross-encoders. I found it genuinely interesting, and it explains why reranking matters so much.
I have been working with embeddings for a while. Embed your documents, store the vectors, compare them at query time with cosine similarity, send the closest results to the LLM. Most people building RAG applications today are doing exactly this. It is the default approach and it makes sense that it is the default. It is fast, it scales, and it works well enough most of the time.
But there is something underneath it that is worth understanding.
When you embed a document, you get one vector back. One fixed point in vector space. That vector has to represent the document for every possible query that might ever come in, before it knows what anyone is going to ask.
A quick example is this: say we have got a restaurant review. “The pasta was incredible but the service was painfully slow.” One query asks for good Italian food. Another asks for restaurants with bad service. Same sentence, completely different relevance depending on who is asking. The embedding already committed to a position before either query arrived.
What I found even more interesting is the negation problem. “I am having a good time” and “I am NOT having a good time” score high similarity in most bi-encoders. Same tokens. Opposite meaning. The architecture does not notice.
The reason this happens is architectural. Embedding models are bi-encoders. The document is encoded independently of the query. They never see each other until the similarity function. That separation is what makes them fast enough to use at scale. It is also what makes them contextually blind.
Cross-encoders work differently. Instead of embedding a single string, they accept two inputs together, the document and the query, and return a number showing how similar they are. Behind the scenes they use the same attention mechanism that LLMs use, which has proven effective at capturing semantic relationships. Because of this, the meaning that gets encoded for a document actually changes based on the question being asked.
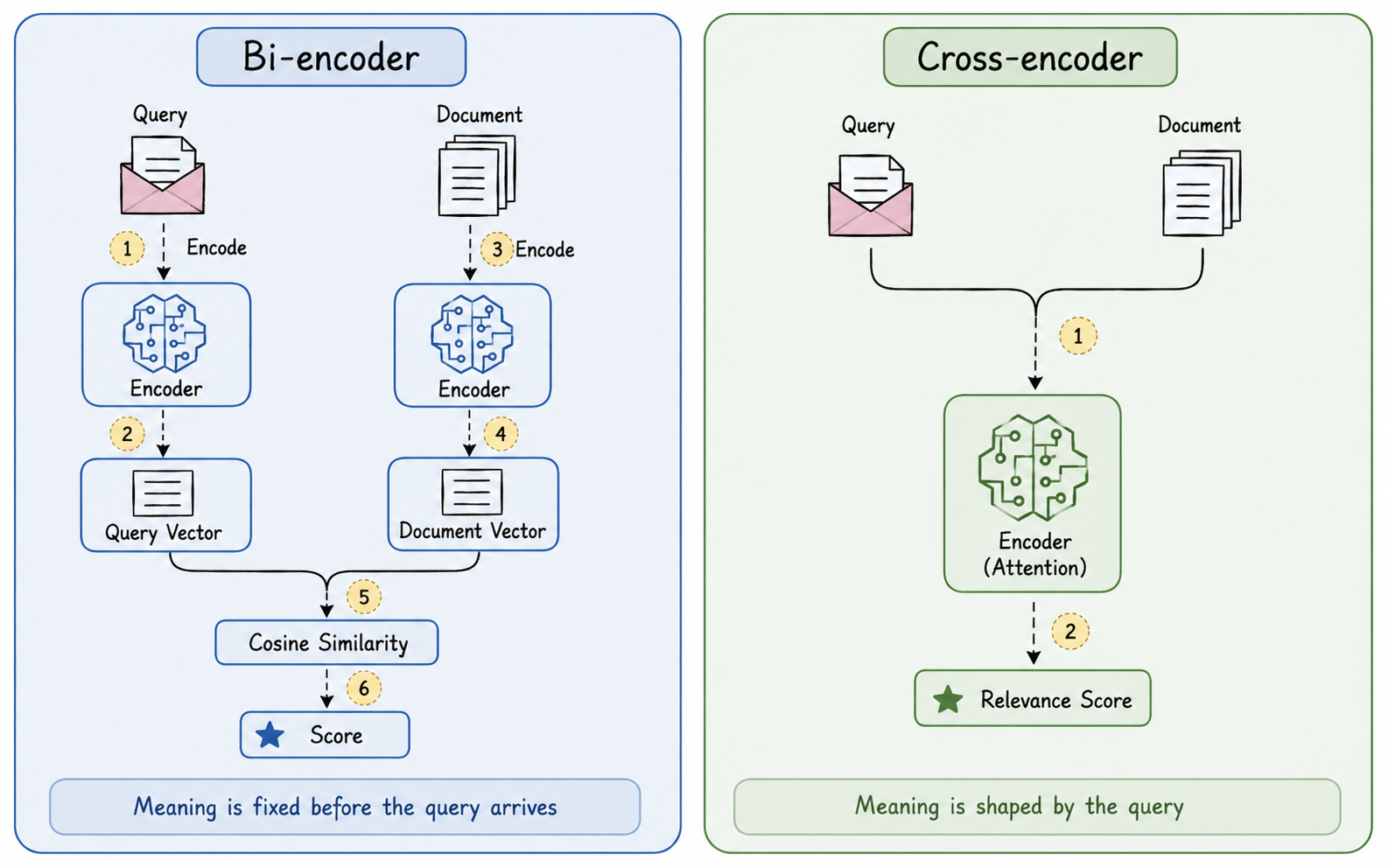
The downside is speed. You have to go through all your documents and the attention mechanism is quite slow, so you cannot run a cross-encoder over a large document store at query time.
The pattern that works is: use a bi-encoder to retrieve the top 20 candidates quickly, then use a cross-encoder to rerank them, then send the top 5, for instance, to the LLM.
The bi-encoder gives you recall. The cross-encoder gives you precision. You need both.
If you want to try it, cross-encoder/ms-marco-MiniLM-L-6-v2 from Sentence Transformers is a good starting point. Drop it between retrieval and generation.
I am still learning about this and would love to know if anyone has run into retrieval quality issues that turned out to be architecture problems rather than chunking or prompting problems.