I benchmarked 5 embedding models across 4 datasets
I benchmarked five embedding models across four NanoBEIR datasets and found that bigger embeddings did not always produce better retrieval.
Bigger embeddings = better retrieval. That has always been my assumption, until I decided to test it.
I benchmarked 5 models across 4 datasets to find out.
For my experiment setup, I did not want to simply compare different models at different dimensions, because model quality is heavily influenced by training data. So I tested with 3 Matryoshka-based models. Matryoshka models have the interesting property that truncated lengths of their embeddings still encode meaning. I find the idea very interesting.
The Matryoshka models I used were OpenAI’s text-embedding-3-small and text-embedding-3-large, and nomic-embed-text-v2-moe. I also threw in two non-Matryoshka models just for context.
I benchmarked these models across 4 NanoBEIR datasets, over 15k docs in total: NanoNQ for open-domain QA, NanoSciFact for scientific claim retrieval, NanoFiQA2018 for finance-style docs, and NanoArguAna for argument retrieval. Each dataset came along with 50 queries.
For indexing and retrieval, I used RedisVL, and I documented the following metrics:
- Retrieval latency
- Hit@10: indicates whether the top 10 retrieved docs contained at least one relevant document
- MRR@10: measures the position of the relevant document in the top 10
- nDCG@10: measures the ranking of documents in the top 10, since some queries mapped to more than 1 document
I whipped up a simple Python app and, a couple of minutes after, the results were interesting to say the least.
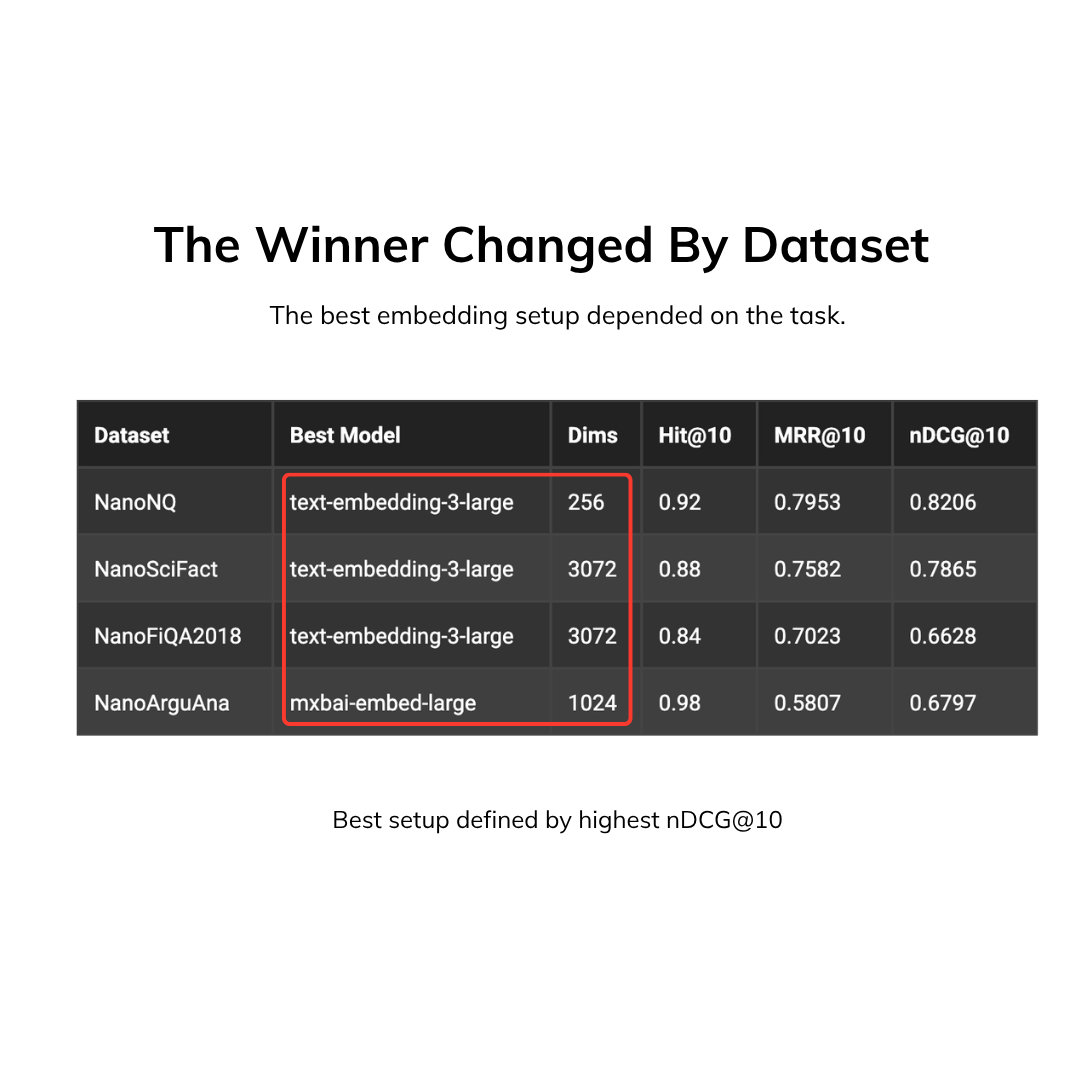
text-embedding-3-large@256was nearly as good astext-embedding-3-large@3072on retrieval quality while being 3.4x faster at retrieval.- There was no singular “best”
nDCG@10embedding model across all the datasets:text-embedding-3-large@256was best on NanoNQ,text-embedding-3-large@3072was best on both NanoSciFact and NanoFiQA2018, andmxbai-embed-large@1024was best on NanoArguAna. - In one dataset, NanoNQ,
text-embedding-3-large@256outperformed the largest model,text-embedding-3-large@3072, on bothMRR@10andnDCG@10.


Quick note: this is a small-scale benchmark, so please treat the findings as directional insights rather than conclusive.
My takeaways:
- Vectors with higher dimensions may preserve more signal, but they can also preserve noise, depending on the model and dataset. This might be why larger is not necessarily better.
- Matryoshka models at lower dimensions might be a simple and practical way to save cost and latency. They are worth testing before using full dimensions.
- External benchmarks are a useful starting point, but they should not define your final embedding model choice. Run your tests on your own data, queries, and models to find what performs best.
If you want to play around with these benchmarks, check out my GitHub page on this: embedding-benchmark. You can also include your own datasets and queries.
I would love to learn from you. Have you run similar benchmarks on your own data?